Ensembling is a powerful approach for improving machine learning performance. This article is part of our introduction to data science.
It involves combining several base machine learning models predictions to produce a final outcome.
The ensembling method can have a better accuracy than all of the base models that are part of the ensembler. This happens when the base classifiers are sufficiently diverse and distinctive.
We will try to illustrate why ensembling methods has such good performance with a help of an example.
Let us say that we have 4 machine learning models that produce classifications for three classes. The result of each base classifier will thus be e.g. 100 which would denote presence of class A (1) and absence of classses B (0) and C (0).
Now let us take some input data Y for which we know that the ground truth result is 110.
If we input these data to our ML classifiers we get the following results:
100 (“error”)
110
010 (“error”)
110
However if we run the machine learning model results through ensembling model that uses majority voting, the result will be correct: 110. Despite two errors.
This example shows why combining machine learning models may lead to better results than the base models.
It also helps explain why there is some truth to the wisdom of crowds.
Ensemble methods
There are several different types of ensembling methods:
- averaging
- bagging
- boosting
- stacking
- blending
Averaging
In averaging ensemble method we simply average the predictions of the individual base models.
Bagging
The bagging works by taking sampling from the train data set with replacement. Note that in such sampling we may obtain train data sets where the same instances may be present more than time. Once we have the sampled train data sets we train base model on these data sets, obtaining several base models.
If you ask yourself about the origin of the name, it comes by taking characters from the Bootstrapping name. Bagging was introduced by L. Breiman in 1994.
A well known example of bagging are random forests which are just decision trees trained on different samples from train data sets.
Where does bagging help us?
One benefit of bagging is that it decreases the variance of the machine learning model. We all know that all machine learning models suffer from the bias variance trade-off. Bias tells us something about how appropriate is the model for the problem and data set. Variance is the sensitivity of machine learning model to the training data set. Machine learning model with high variance will change greatly if we replace train data set with other instances.
Boosting
What about the bias? Well, we can reduce it by using the boosting approach.
In this case we train our base models sequentially. We train the first base model on our data and then reweight instances for which we got poor predictions. Then we train the next base model on this modified data and repeating these steps. The main idea is that the next base model tries to perform well on instances for which there was poor performance by previous base models.
Many boosting algorithms have been developed over the years, e.g. AdaBoost, Gradient boosting and XGBoost.
Finally, let us consider stacking ensembling method. In stacking we have base models and additional meta model which trains on the out of fold predictions of the base models.
We could e.g. build the following base models:
- logistic regression
- linear regression (lasso, ridge)
- decision trees
- random forests
- support vector machine
- gradient boosting machine
- xgboost
- lightbm
- lstm deep neural net
- cnn neural net
Diagram of base models and meta model for stacking:
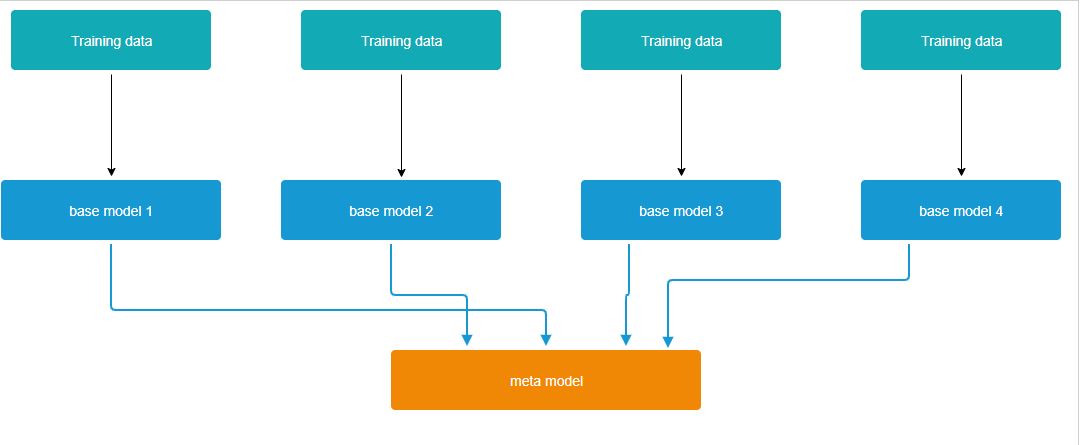
For meta model we can use logistic regression, lasso regression or XGBoost.
Stacking is trained in two major steps:
- train the base models with k-fold validation, set aside the out of fold predictions of the base models
- train the meta model on these out of fold prediction
Blending
Blending is slightly different to stacking.
Blending uses the held out validation set instead of out fold predictions, typically 10% of instances are used for this purpose.
AI Content Writing
In the second part of our article we will discuss recent advances in the field of AI Content Writing. In recent years there has been a lot of great steps in the natural language processing. In computer vision, a big step was the Imagenet competition and the big improvements made as part of it, e.g. AlexNet, Resnet, VGG and other great models which significantly improved performance over prior best results.
In natural language processing consulting we judge that a similar moment was achieved with great improvements in main language tasks with BERT or Bidirectional Encoder Representations from Transformers.
BERT has achieved great progress in many NLP tasks, such as Question Answering (SQuAD v1.1), Natural Language Inference (MNLI), and other tasks.
Another great leap was the GPT 2 model of OpenAI. It is particularly suited for content generation. Initially, OpenAI released only the smallest 110M model with 110 million parameters, in February 2019. They have released bigger models over time with the latest released being the original best one 1.5B.
Journalists and others testing this model were greatly impressed with its performance. Content writing services for AI and other fields may be affected by these developments in the next years. It is possible that new services will be started that will offer high quality AI content writing at a smaller price than the human writers.
GPT2 content generation also already led to interesting applications, e.g. the game AI Dungeon 2 has attracted a large number of users after its launch.